Electronic ISSN 2287-0237
Utilization management (UM) has been effectively used as one of the approaches to reduce consumption of unnecessary healthcare services and thus helps contain cost. It is particularly important in the health insurance industry, due to moral hazard effect that changes patient and physician behaviors and results in overutilization of resources.1,2
A range of utilization management procedures have been deployed by third-party-payers to prevent inappropriate admission. Pre-authorization is a widely-used technique to certify the need for hospitalization and medical care, but it contributes to administrative burden and may delay necessary services. As a result, most insurance companies in Thailand implement a pre-authorization process for non-urgent surgical procedures and high-cost diagnostic procedures only, leaving non-surgical cases to be submitted and adjudicated after the services have already been delivered. Unexpectedly rejected claims can sometimes cause confusion and frustration to patients. Due to the aforementioned reasons, concurrent review is currently a main monitoring measure performed by both insurance companies and hospitals to ensure medical necessity of resource utilization during hospitalization. The concurrent review criteria may be either referred from guidelines or determined by specific clinical attributes such as severity of illness and intensity of services.3 Both approaches require initial screening which are normally performed by utilization review (or management) nurses (UR or UM nurses) to compare patient’s clinical conditions, includ- ing both objective data (e.g. blood pressure, body temperature, laboratory and imaging results) and subjective data (e.g. chief complaint, present illness, physical examination) to a set of criteria. The data to be reviewed are from various sources such as Hospital Information System (HIS), peripheral systems, and medical records. In addition to the difficulties in complicated and time-consuming review process, human errors from data oversight have occurred frequently due to data overload.4 Moreover, the reviewers’ performance and accuracy of review results largely depend on the individual’s clinical knowledge, cautiousness, and experience. An inexperienced UM nurse might not be able to prioritize work and spend time on low-value tasks, making unnecessary utilization of resources unattended and subsequently causing difficulties among the patient, provider, and payer.
The growth of health insurance industry in Thailand has more than doubled in the past 7 years. Total health insurance premium per annum has continuously increased from 43.4 billion in 2012 to 91.5 billion baht in 2019.5 This indicates the increasing demand of human resources for both insurance companies and hospitals to handle claim processes and concurrent review. In the US, automated processing and assessment systems have been invented to reduce administrative burden, paperwork, cost, and also to support decision making process.6-8 The feasibility of Natural Language Processing (NLP) for narrative medical record processing was explored as early as 1981 by Hirschman who used NLP to analyze discharge summary, implemented evaluation criteria, gener- ated evaluation results, and compared to those from physician reviewer.9
Currently, extensive AI-enhanced solutions have been of- fered by many IT companies to lessen UR efforts, such as Case Advisor Services by Optum360° and CORTEX®: The Precision Utilization Management Platform by XSOLIS.10,11 However, those may not be suitably applied to the insurance industry in Thailand due to different language of medical record documentation and different contextual factors, especially the high proportion of inappropriate “simple diseases” admissions.12 These diseases can normally be treated in outpatient department. Moreover, Thai Natural Language Processing has continuously evolved for decades but is not yet fully developed due to words and sentences complexity of Thai language.13 Hence, new methods or innovative approaches should be introduced to address these problems.
Research and development on machine learning and deep learning in NLP tasks have advanced dramatically. Many progressed machine learning models were developed from the neural network and the variances of it, and each of them has different characteristics and applications. Some research has been conducted on implementing Convolutional Neural Network (CNN) in a sentence classification task and achieved excellent results, even when the training data came from many sources.14 Moreover, there is research that implements Recur- rent Convolutional Neural Network, a hybrid neural network in a sentence classification task, by integrating CNN and Long-Short Term Memory (LSTM) so that the model can capture contextual information.15,16 As for the problem of Thai language in NLP, PyThaiNLP was developed specifically for this issue.17 It can segment and tokenize Thai words efficiently and was selected as a tool in our task.
Although a health information entry in a structured format tremendously supports subsequent computer processing, nar- rative language and semi-structured data may have superior advantages of comprehensiveness, clinician’s thought process, and fine structure representation.18
As a result, Bangkok Dusit Medical Services, Plc., (BDMS), the largest private hospital network in Thailand, designed and internally developed “BDMS Utilization Review Technology (BURT)” as a decision support application to detect inappropriate hospitalization using natural language processing and a rule-based approach. The implementation of BURT will significantly reduce the assessment processing time performed by UM nurses, since it immediately captures all necessary data at their fingertips. The precision of review results is expected to be higher than those performed by inexperienced UM nurses who occasionally missed crucial data. Moreover, BURT should help expediting the claim process since it will help prioritizing cases that require atten- tion and prompt actions, such as to improve quality of clinical information provided to payers or to clearly communicate to patients regarding unnecessary hospitalization requests.
Among several techniques of machine learning, Neural Network processing is very popular due to its broad learning abilities. As a result, various models have been applied. Convolution Neural Network (CNN) is an advanced form of neural network that can group sentences with a great variety of semantic categories and has been tested with four types of the CNN’s default management model.14 With the Recurrent Convolution Neural Network and Hybrid Neural Network research that apply the Long-Shot Term Memory to CNN to increase the ability to learn, CNN can learn the continuation of various sentence styles15,16 and be more efficient with different structure.19 However, due to the complexity of the internal structure of CNN, which is caused by the application of hierarchical mathematical procedures, there are mysteries that many researchers are trying to understand and interpret. To be able to properly provide information and increase work efficiency20 from these successful researches, it is part of the approach and inspiration to apply CNN to Natural Language Processing (NLP).
Using the CNN in the BURT program allows us to abstract and interpret free-text data in medical records to see if a word or sentence meets certain criteria. The system has a set algo- rithm based on data from both NLP and rule-based approach.
Establishment of admission criteria based on current medical standard of practice
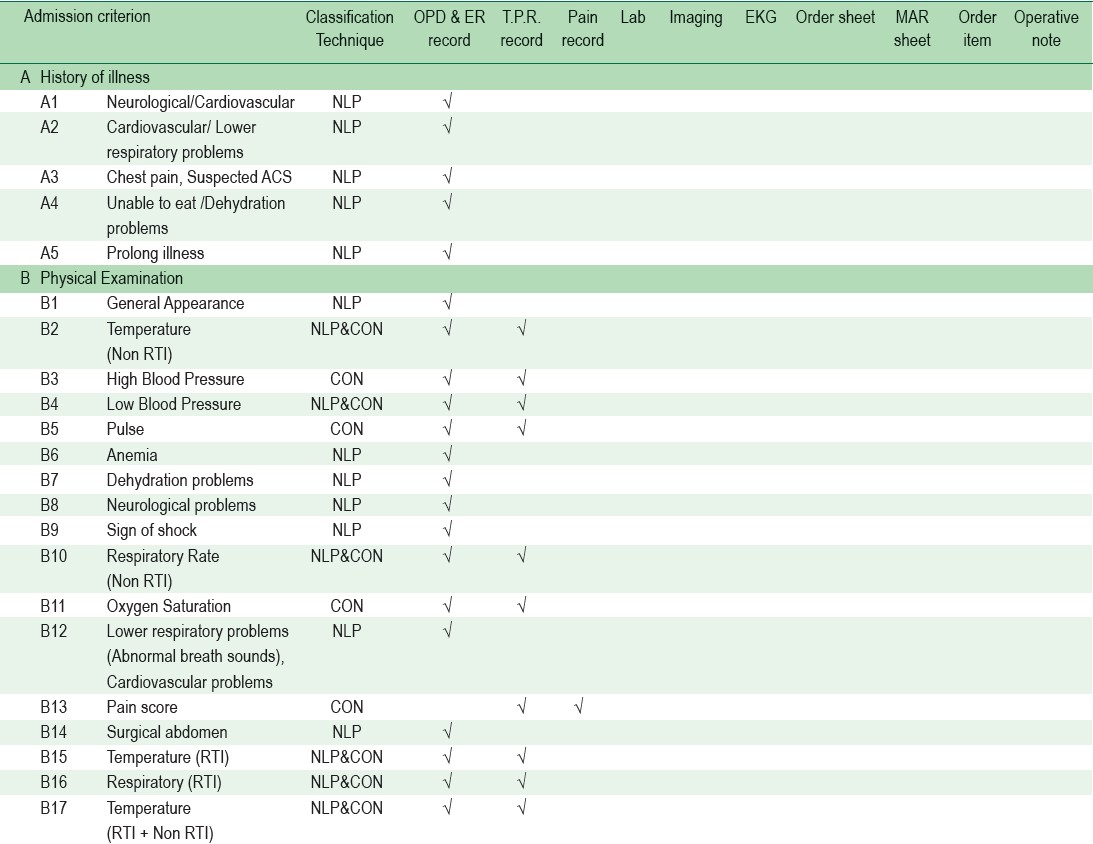
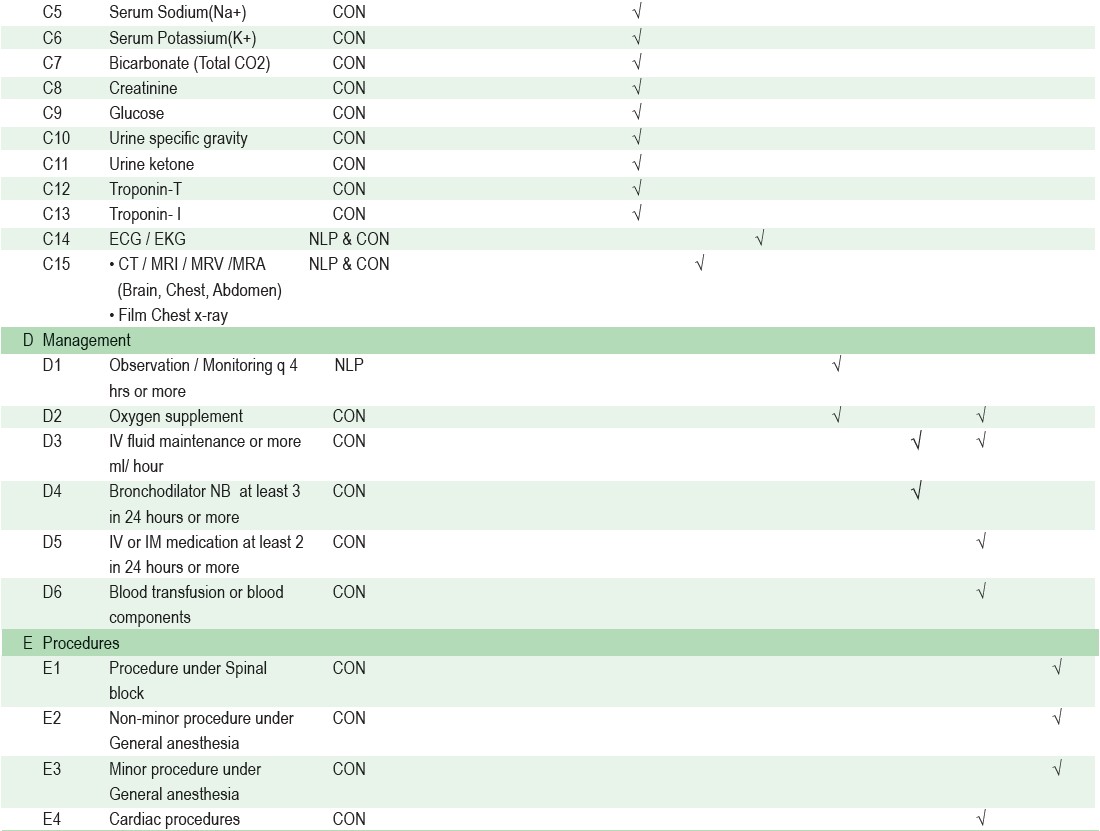
To make the tool worthwhile and suitably applicable for the Thai context, it should be able to address a common problem of unnecessary simple disease admissions. Since the definition of simple disease is not universally agreed upon and there is no gold standard of admission guideline for simple disease, we appointed an expert panel of UM physicians including 5 physicians from different specialties and different hospitals. All of them have more than 10 years of medical practice experience and over 2 years of UM physician experience. The panel studied and compiled criteria from several sources including up-to-date, guidelines from The Royal College of Physicians of Thailand, National Clinical Practice, etc. 21-26 and subsequently developed a comprehensive guideline for appropriate hospitalization. The details of 48 criteria variables were defined as A1 to F1 and can be seen in Appendix A.
Development of BDMS Utilization Review Technology (BURT) Web Application
We designed and developed BURT web application to evaluate appropriateness of hospitalization. It consists of two main components, including Prediction Model (AI and Rule-based) to analyze appropriateness of hospitalization based on admission criteria, and Display Application to present predicted result of each case.
Development of prediction model (BURT version 1.0)
We acquired data from a hospital in BDMS network where electronic medical records (EMR) have been completely implemented. Anonymized data of insured-patients admitted from January to May 2019 (1,000 cases) were included to build a prediction model. (Demographic information can be found in Appendix B). This dataset was used for the development of prediction model, both AI (Natural Language Classification Model) part and rule-based prediction part. Free-text documented dataset from History of illness, Physical examination,and from some physicians’ order notes, contributed to development of Natural Language Classification Model.
From admission criteria, we defined 65 terms for NLP training, for example “cannot walk”, “weakness in arms and legs” “mental status change”, “swollen face”, “swollen eyelid”, “very fatigued” etc. for B1 criterion - General Appearance. These were sorted from the abovementioned dataset, which made altogether 9,870 sentences. Data were randomly selected into two sets of 80% (7,896 sentences) for model training and 20% (1,974 sentences) for model testing. From all text data, sentences were split into words for training with PyThaiNLP (Appendix C), which is a Python library to truncate words.17 A word segmentation technique was deployed in both training step and testing step in our research. A window size of 7 was used (7 before and 7 after the context word). The expert team made labels of each phrase to indicate whether those phrases corresponded with desired criteria, using the binary codes of 1 for corresponded and 0 for not corresponded. Again, PythaiNLP package can facilitate transformation of words encoding into randomly vectorized numerical data for CNN training in the next step.
Labeled data and data from word tokenization was trained using CNN model, which consists of 2 layers, 3x1 convolutional layer and dense layer. For dense layer, the number of neural network nodes depended on the number and complexity of the training sentences, making the overall model consists of multiple models.
The trained CNN model was implemented for each single NLP criterion and provided a predictive result from all medical sentence input. Therefore, each NLP criterion will be classified as “Met” or “Not Met”. Flow chart of Natural Language Classification model of this project is shown in Figure 1. The performance using testing data as an input achieved 95% accuracy.
A rule-based module was set up with conditional values taken from vital signs, laboratory results, and computerized physician order entry (CPOE) (Table 1). The criteria rule was based on a comprehensive guideline for appropriate hospitalization compiled by UM Physician Panel. This combined AI and rule-based algorithm was then able to evaluate appropriateness of admission and show results as “Appropriate hospitalization” or “Inappropriate hospitalization”.
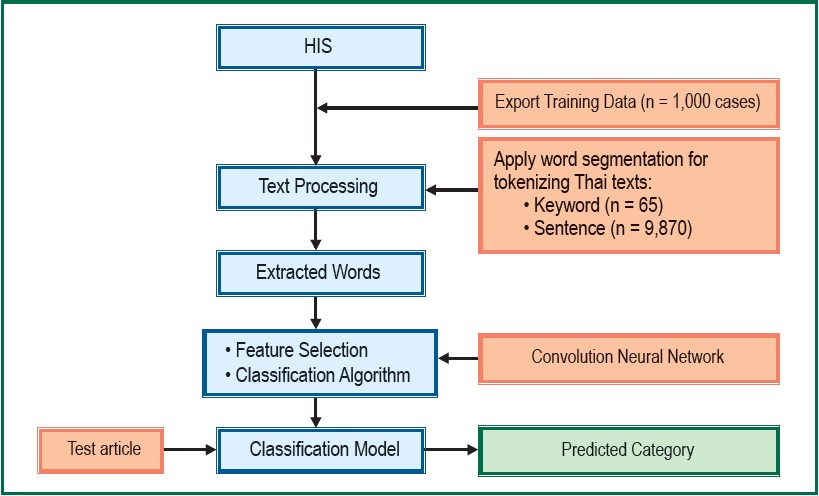
Figure 1: Flow Chart of Natural Language Classification Model (BURT 1.0)
Table 1: Dependent variables and clinical data sources used by BURT predictive algorithm


Data from 500 cases, which were the subset of 1,000 cases (Appendix B), were randomly selected and comprehensively studied by the UM physician expert panel. A series of collaborative discussions among UM Physicians gearing towards final agreement for each case was made from a majority vote. The mutual goal was threefold: to improve NLP accuracy, to evaluate appropriateness of admission criteria algorithm setup, and to evaluate the effectiveness of automated application of the criteria. We aimed to make BURT capable of analyzing appropriateness of hospitalization in both simple diseases and non-simple diseases with various levels of severity. During the fine-tuning process, we increased keywords for NLP training (from 65 to 79 terms), and increased NLP training and testing dataset (from 9,870 to 77,707 sentences). The anonymized data of insured-patients admitted between December 2017 and October 2019 (22,020 cases) were included. The rule-based model was also enhanced from condition-based to scoring-based in order to classify different levels of severity. After the fine-tuning process, tremendous improvement was made from our first to the latest version of the tool, and can be described as BURT 1.0 and BURT 1.1 respectively. Examples of major improvement are explained in Appendix D.
After several consecutive cycles of NLP training and testing, we achieved great results of NLP model with significantly increasing accuracy, precision, recall, and F1-score. (Table 2). The definition of each matrics can be seen in Figure 2.
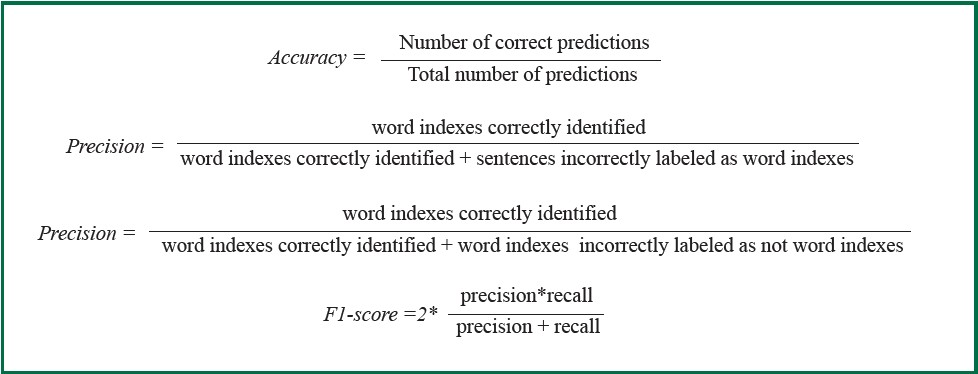
Figure 2: The definition of evaluation matrics.
Table 2: Confusion matrix for NLP predicted model in BURT 1.0 and BURT 1.1
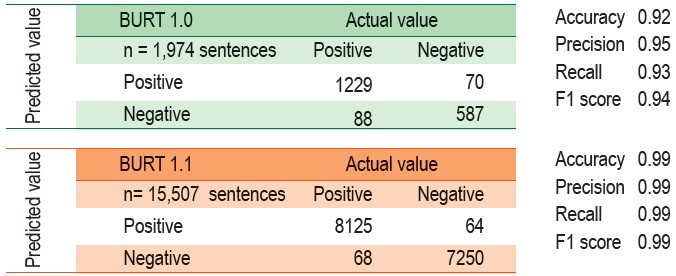
The agreement between BURT 1.1 and UM Physician Panel also increased significantly from 70% to 85% (Table 3). We intended to minimize the number of false positive (false appropriate), since it will make UM nurse inadvertently rely upon the predicted results and overlook any issues that require a necessary action. We then thoroughly reviewed all the 14 false positive (false appropriate) cases and found out that the agreements on inappropriate hospitalization among UM Physician Panel were not unanimous. Ultimately, BURT 1.1 showed very promising predicted results. However, given that advanced medical technology and treatments are continuously being evolved, we will continue to align our tool accordingly.
Display Application
The predicted results are displayed on web application. The dependent variables of appropriate hospitalization decision were categorical and have three possible results: appropriate admission, borderline inappropriate admission, and inappropriate admission. (Figure 3 and Figure 4)
The prediction outcome and detailed information for each criterion will be displayed on the screen so that users can take suitable further action, or to notice the weakness of algorithm, or even to make recommendation and give feedback to the application administrator. 27
Table 3: Confusion matrix for appropriate vs inappropriate hospitalization predicted by 2 versions of BURT
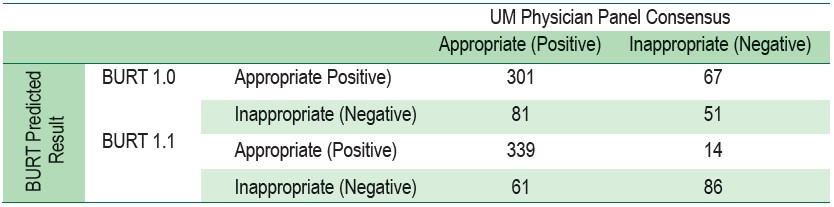
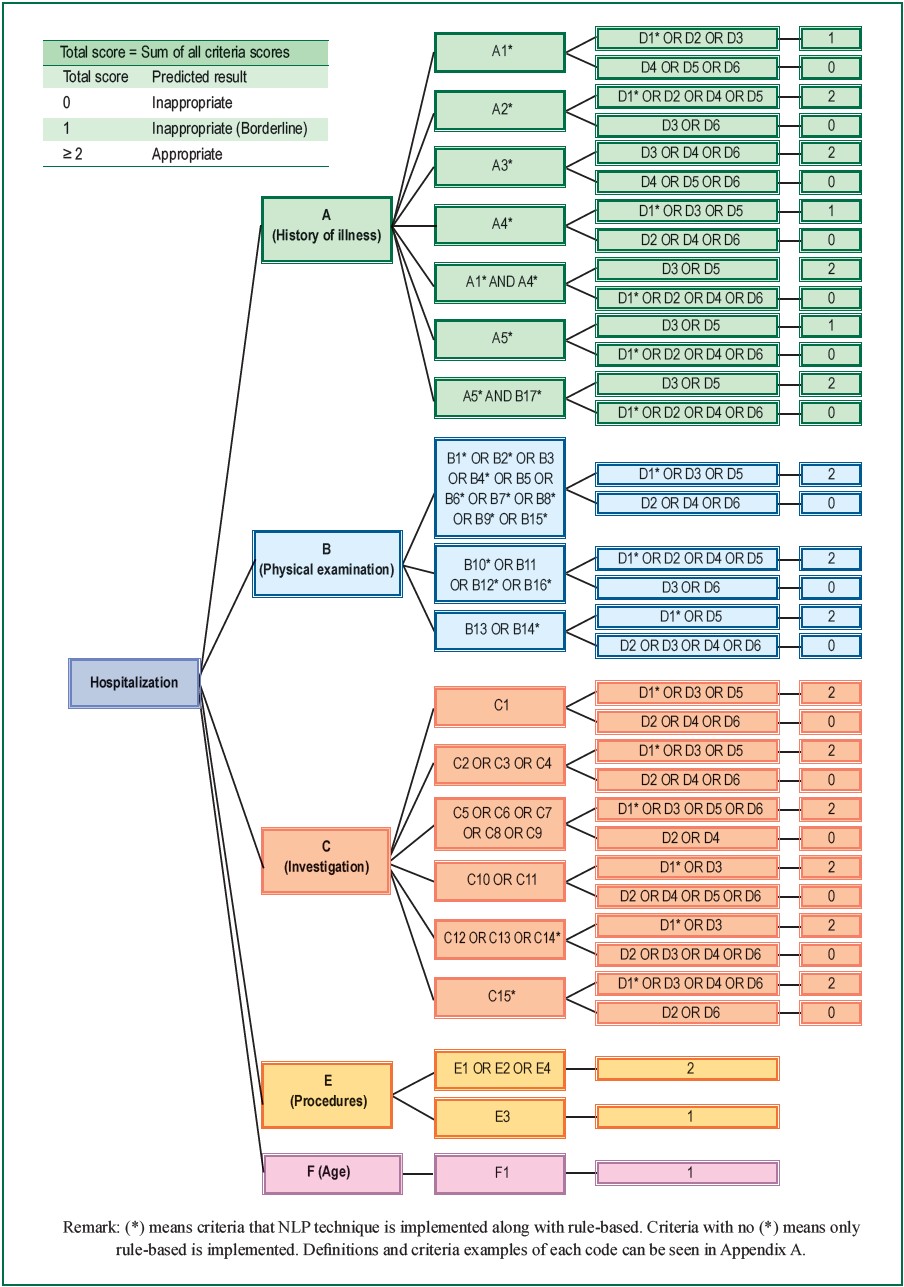
Figure 3: Admission criteria scoring system implemented in BURT 1.1: NLP and rule-based algorithm
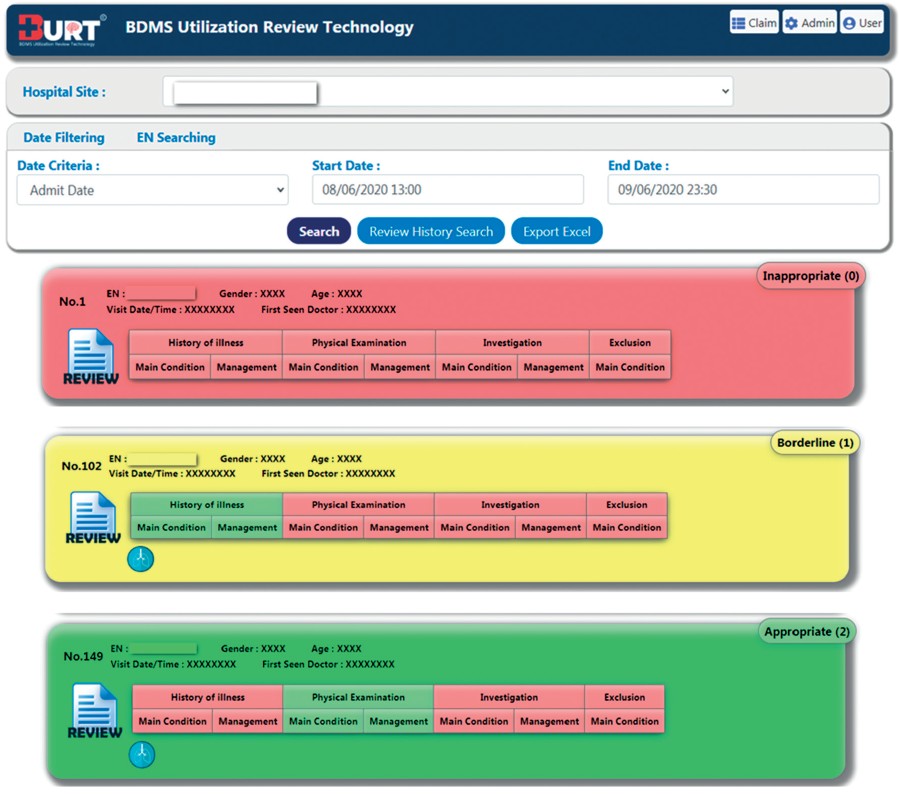
Figure 4: Screen shot of BURT1.1 displaying prediction results on hospitalization appropriateness.
BURT1.1 performance evaluation
We evaluated the performance of BURT1.1 in assessing inappropriate hospitalization by comparing its results to those manually performed by UM nurses. Using the identical 300 cases, we compared the review results from three sources, including BURT1.1, concurrent review data collection from the participating hospital, and retrospective review report from Bangkok Hospital Headquarters. Firstly, we randomly selected 300 cases from 500 cases that had been thoroughly reviewed by UM Physician Panel and made a consensus on appropriateness of hospitalization. Secondly, we searched for the review results of those 300 cases that were manually reviewed by UM nurses in the participating hospital and concurrently reviewed during patient stay. Thirdly, we retrieved detailed clinical data of 300 cases from important sources that required by BURT1.1 algorithm and summarized them in a ready-to-review excel form, and assigned to UM nurses at Bangkok Hospital Headquarters. Three UM nurses with different levels of experience, including 1 in-charge UM nurse and 2 operational-level UM nurses were specifically selected to perform secondary analysis of retrospective data. The criteria set was clearly explained prior to the review process in order to reduce variance. Rate of agreements on detection of inappropriate hospitalization between UM Physician Panel and BURT1.1, UM Physician Panel and concurrent review report from the network hospital, and UM Physician Panel and retrospective review report from Bangkok Hospital Headquarterwere then compared (Table 4).
Table 4: Rates of agreement between UM Physician Panel and different methods of review, namely BURT1.1, concurrent review by UM nurses at network hospital, and retrospective review by UM nurses at Bangkok Hospital Headquarter (BHQ).
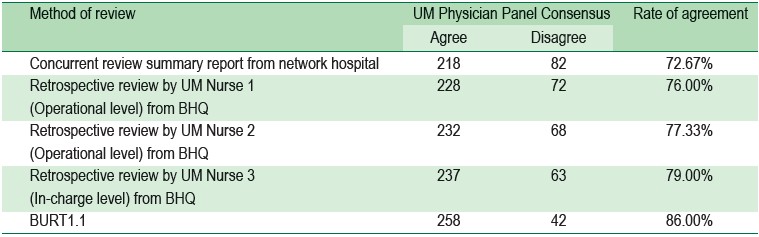
Overall, BURT1.1 showed a favorable outcome with the highest rate of agreement (86.00%) among all the methods. An in-charge UM nurse and two operational-level UM nurses from Bangkok Hospital Headquarters had 79%, 77.33%, and 76.00% respectively. Network hospital showed the lowest rate of agreement (72.67%), presumably from excessive workload and a laboriously manual review process that all the scattered sources of information might easily lead to data oversight.28 The performance evaluation results demonstrated that BURT1.1 can support utilization review process in detecting inappropriate admission and leading to an appropriate action that should be taken by a UM nurse.
BURT1.1 prediction output and insurance claim approval
We retrospectively evaluated the insurance claim adjudication decision made by insurance companies for those 300 cases (Table 5). The claim approval apparently aligned with the BURT1.1 prediction outputs. As we prioritized precision over recall, 99% of precision represented a satisfied prediction outcome. There were three cases that BURT1.1 predicted output showed appropriate, but the claims were denied by insurance companies. We thoroughly reviewed the reason of claim denial for these three particular cases and found out that they were non-clinical issue of suspected preexisting conditions. On the other hand, in Thailand, the claim denial rate for inappropriate hospitalizations was relatively low due to the fact that various factors are usually incorporated in claim adjudication process especially special business condition that can overrule medical necessity and insurance policy details. However, BURT1.1 was not designed to predict claim approval decision and will definitely assist UM nurses in detecting medically inappropriate admission, inappropriate documentation, and patient’s request for unnecessary admission. One case rejected by an insurance company due to unnecessary admission, for instance, BURT1.1 would have displayed the unmet criterion which was actually from incomplete documentation. Feedback to physician should have been provided immediately to improve medical record documentation.
Table 5: Confusion matrix of BURT1.1 prediction output and insurance claim approval

Time and cost -saving utilization review process
Processing time of conventional admission review that has been manually performed by UM nurses, varies between 10-15 minutes per case, depending on UM nurse experience, medical knowledge, and competency. Within 0.59 seconds, BURT1.1 can provide a prediction result output, this allows UM nurses to perform more valuable tasks, increases productivity, and reduces operating costs. For example, for the total of 300 cases in our BURT1.1 performance evaluation, UM nurses could have dismissed 206 (69%) cases, and directly focus on only 94 cases.
The significance of our study is that the predictive algorithm development process has been exhaustively refined by a UM physician expert panel. Additionally, the combination of Thai natural language processing and a rule-based model, which runs on web application, makes it highly applicable for other hospital settings. However, pre-required electronic medical record (EMR) and computerized physician order entry (CPOE) are unavoidable, since the tool needs electronic records for rule-based approach.
A limitation of this study is that the data is from only one hospital, so overfitting could be a problem that we would expect to encounter due to specific practice patterns and clinical cultures of each hospital. Similar to other previous studies, no clinical NLP algorithm is completely accurate and we also found the same challenges of missing information or medical narrative explaining severity of illness, not in a guideline terminology format but implicitly stated in documents.27, 29
BURT1.1 will be implemented as an automatic routine screening tool in a pilot hospital in the BDMS network. It will capture data directly from the Hospital Information System (HIS) and related peripheral systems, and perform hospitalization appropriateness evaluation. However, further work needs to be contributed by both developers and users to make the tool functioning more accurately and to fix the overfitting problem. Under certain circumstances, disagreement between BURT1.1 and human expert may occur and should be discussed with an application administrator. Potential improvement would be to refine the precision of NLP and measure sensitivity and specificity of the tool. Advanced scoring system for severity of illness, including patient’s chief complaint, clinical signs, and symptoms, should be established to provide probabilistic outputs in more details. Additional thesaurus of signs and symptoms may be required for extra training. The tool should be directly integrated into BDMS e-Claim system and shared display application in order to perform real-time evaluation. To make the tool easily applicable to analyze evidence-based guideline compliance for other resource utilization, such as appropriateness of diagnostic and therapeutic services, we plan to enhance NLP tasks to be able to extract temporal information, track longitudinal progression of an illness, 30 and transform unstructured data to structured data. 31
Through several collaborative discussions among Utilization Management experts with available electronic health record (EHR) data, we developed an AI enhanced tool using Natural Language Processing and Rule Based algorithms, namely BDMS Utilization Review Technology (BURT) and have improved version as BURT1.1. This BURT1.1 should be effectively implemented as an automatic daily screening tool for inappropriate hospitalization, which is a first level review process of utilization management. It can immediately identify records at high risk of inappropriate hospitalization that require further manual review by UM nurse, provide feedback to attending physician on the completeness and quality of documentation, as well as notifying the case to be reviewed by UM physician. BURT1.1 will also be beneficial to UM nurses to develop their knowledge and professional judgement, since it will clearly show on the display screen how patient’s data satisfies each specific criterion. Ultimately, the use of BURT1.1 would increase UM efficiency, expedite the claim process due to more complete data submissions, reduce health care costs from unnecessary hospitalization, and reduce claim denials.
We thank members of UM expert panel, (Piemchok Banomyong, MD, Suwapat Dewan, MD, Chatchai Charoensri, MD, Wittaya Konngam, MD, Naruenart Koovimon, MD), UM nurses of both participating hospital and Bangkok Hospital Headquarters. Behind every step, we received technical support from hospital IT staff, GreenLine Synergy teams and Wuttichai Luangruangrong, PhD. We thank them for that. Finally, this study would never been completed without management supports of Mrs. Narumol Noi-am, Senior Ex- ecutive Vice President of BDMS, Trin Charumilind, MD-Chief of Doctors, Matinee Maipang, MD-hospital director of Bang- kok Hospital Headquarters, and hospital director of the par- ticipating hospital.









